MapReduce
A lógica por trás do modelo
O MapReduce é um modelo de programação desenvolvido pelo Google em 2004 para facilitar o processamento de grandes volumes de dados por meio de computação distribuída. Embora o modelo tenha sido amplamente adotado através de frameworks como o Hadoop MapReduce, ele já não é o padrão predominante nem mesmo dentro do Google, que passou a utilizar soluções mais modernas. Diante disso, será que ainda vale a pena estudar esse modelo?
Considerando que o MapReduce foi um dos primeiros frameworks realmente escaláveis a serem aplicados em produção, ele se tornou uma referência fundamental na história do processamento distribuído. Por isso, ainda há boas razões para que engenheiros de dados aprendam seus conceitos — não apenas por sua relevância histórica, mas também como base para compreender arquiteturas e ferramentas modernas como Apache Spark e Apache Beam.
- MapReduce introduziu muitos dos conceitos fundamentais de processamento distribuído que são utilizados por tecnologias mais modernas. Entender MapReduce ajuda a construir uma base sólida para compreender como e por que essas tecnologias funcionam.
- Conhecer os conceitos de mapeamento, redistribuição, ordenação e redução é crucial para entender como os dados são distribuídos e processados em paralelo.
- Conhecer a evolução das tecnologias de Big Data desde o MapReduce até o Spark pode proporcionar uma melhor compreensão dos desafios que foram resolvidos ao longo do tempo.
- MapReduce foi uma inovação significativa em seu tempo e muitos conceitos e técnicas desenvolvidos para ele ainda são aplicáveis e relevantes.
- Muitas organizações ainda podem possuir infraestruturas Hadoop que utilizam MapReduce. Conhecimento de MapReduce permite trabalhar e manter esses sistemas legados de forma eficaz.
- A capacidade de migrar ou integrar sistemas baseados em MapReduce para tecnologias mais modernas pode ser uma habilidade valiosa.
- Conhecimento em MapReduce pode ajudar a identificar e resolver problemas de desempenho em sistemas que utilizam essa tecnologia.
- Entender os gargalos e otimizações do MapReduce pode ser útil para ajudar nas tarefas de otimização de desempenho de qualquer pipeline de dados distribuído.
Agora que você já sabe que vale muito a pena estudar o MapReduce, como ele funciona?
A arquitetura do MapReduce é composta por componentes ou passos: os usuários definem uma função map que processa dados de input e geram um conjunto intermediário de chave/valor que após será “reduzida” em uma função reduce que agrega todos os valores associados a mesma chave intermediária. Diferentes tipos de tarefas podem se beneficiar desse modelo.
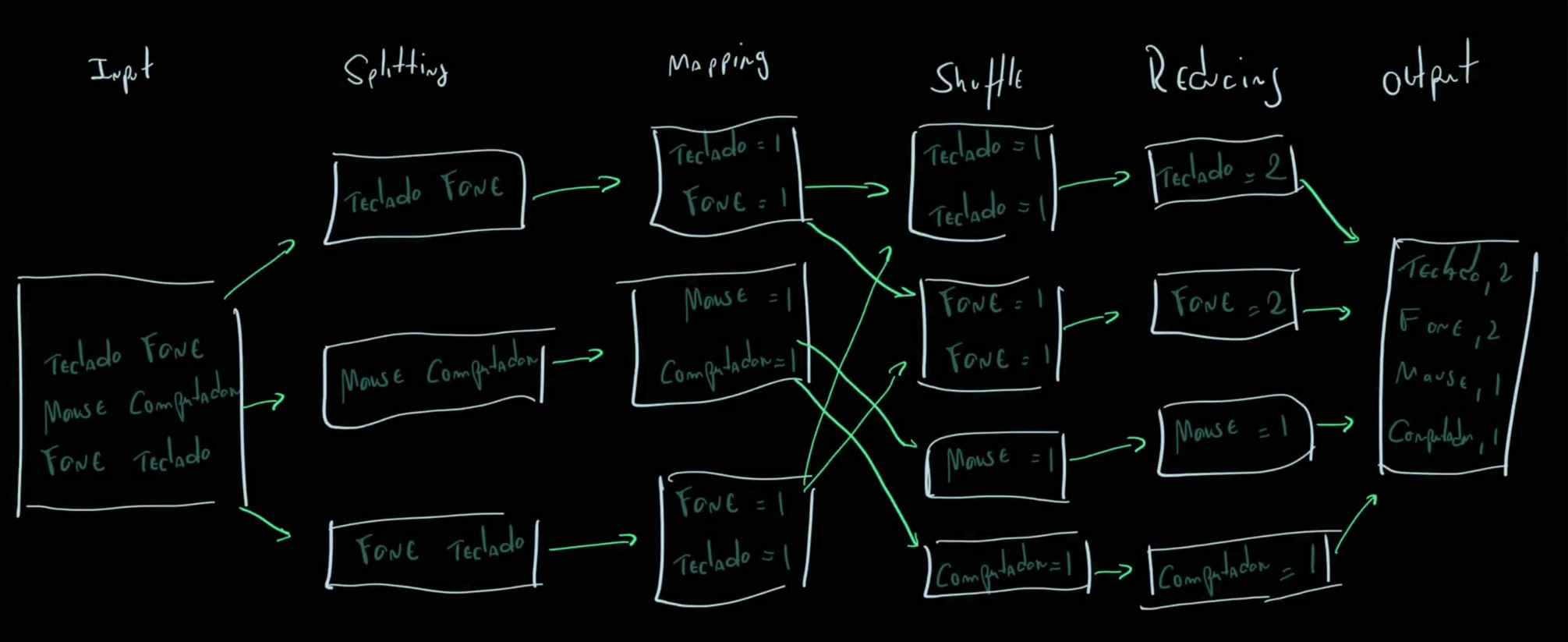
De modo geral, podemos considerar 4 etapas no funcionamento desse modelo de programação. A primeira fase é o splitting, que promove a separação do input inicial em diferentes chunks de dados que serão paralelizados em processamento. Em sequência acontece o mapping, que já detalhamos acima, logo após o shuffle que é uma etapa pré-reduce, no shuffle os workers redistribuem os dados com base nas chaves resultantes da fase de mapping. E por fim, acontece de fato a fase de reduce, também já detalhada no parágrafo anterior.
Bacana, agora vamos entender isso tudo um pouco melhor com alguns códigos em Python para facilitar a compreensão desses conceitos e fluxo?
Para entender melhor a lógica e arquitetura do MapReduce, vamos implementar um caso didático em Python simulando esse método. Não vamos utilizar a biblioteca Mrjob, utilizada para rodar jobs de hadoop mapreduce, justamente para estudarmos em maiores detalhes esses conceitos.
Exemplo Prático
from collections import defaultdict
import threading
#Função para dividir o texto em várias partes para a parelização do processamento
def split_data(text, num_parts):
#Divide o texto em linhas
lines = text.split("\n")
#Calcula o tamanho de cada chunk
chunk_size = len(lines) // num_parts
#Cria uma lista de chunks com o tamanho calculado
chunks = [lines[i * chunk_size: (i + 1) * chunk_size] for i in range(num_parts)]
#Se houver linhas restantes, adiciona-as como um último chunk
if len(lines) % num_parts != 0:
chunks.append(lines[num_parts * chunk_size:])
#Retorna os chunks
return chunks
#Função da fase de mapeamento (Map)
def map_phase(lines):
mapped = []
#Para cada linha no pedaço de texto
for line in lines:
#Divide a linha em palavras
for word in line.split():
#Adiciona cada palavra como uma tupla (palavra, 1) à lista mapped
mapped.append((word.lower(), 1))
return mapped
#Função que será executada por cada thread de mapeamento
def map_worker(text_chunk, results):
#Executa a fase de mapeamento no pedaço de texto
mapped = map_phase(text_chunk)
#Adiciona o resultado do mapeamento à lista de resultados
results.append(mapped)
#Função para coletar e redistribuir os resultados do mapeamento
def collect_and_shuffle(mapped_results):
shuffled = defaultdict(list)
#Itera sobre cada resultado mapeado
for mapped in mapped_results:
#Para cada par (chave, valor), adiciona o valor à lista correspondente à chave
for key, value in mapped:
shuffled[key].append(value)
return shuffled
#Função que será executada por cada thread de redução
def reduce_worker(key, values, results):
#Calcula a soma dos valores associados a uma chave
reduced_value = sum(values)
#Adiciona o resultado reduzido ao dicionário de resultados
results[key] = reduced_value
#Função principal que coordena o MapReduce distribuído
def distributed_mapreduce(text, num_mappers, num_reducers):
#Divide o texto em pedaços para os mapeadores
chunks = split_data(text, num_mappers)
#Fase de Mapeamento
map_results = []
map_threads = []
for chunk in chunks:
#Cria uma thread para cada pedaço de dado
t = threading.Thread(target=map_worker, args=(chunk, map_results))
t.start()
map_threads.append(t)
#Aguarda todas as threads de mapeamento terminarem
for thread_map in map_threads:
thread_map.join()
#Fase de redistribuição e Ordenação
shuffled = collect_and_shuffle(map_results)
#Fase de Redução
reduce_results = {}
reduce_threads = []
for key, values in shuffled.items():
#Cria uma thread para cada chave a ser reduzida
t = threading.Thread(target=reduce_worker, args=(key, values, reduce_results))
t.start()
reduce_threads.append(t)
#Aguarda todas as threads de redução terminarem
for thread_reduce in reduce_threads:
thread_reduce.join()
#Retorna os resultados finais da fase de redução
return reduce_results
#Teste com um exemplo simples
text = """hello world
this is a test, for studying mapreduce
hello world again, mapreduce again."""
if __name__ == "__main__":
#Executa o MapReduce distribuído com 3 mapeadores e 3 redutores
result = distributed_mapreduce(text, num_mappers=3, num_reducers=3)
print(result)
Output

Explicando o código
Importações de bibliotecas
from collections import defaultdict: Importa defaultdict, uma estrutura de dados que facilita a criação de dicionários com valores padrão.import threading: Importa a biblioteca threading para criar e gerenciar threads.
Funções
split_data
- Divide o texto em linhas usando
text.split("\\\\n"). - Calcula o tamanho de cada chunk com base no número de partes desejado.
- Divide o texto em chunks de tamanho aproximadamente igual.
- Retorna os chunks como uma lista de strings.
map_phase
- Recebe uma lista de linhas.
- Para cada linha, divide-a em palavras e converte cada palavra em minúsculas.
- Retorna uma lista de tuplas
(palavra, 1)para cada palavra encontrada.
map_worker
- Executada por cada thread de mapeamento.
- Chama a função
map_phaseno chunk de texto fornecido e adiciona o resultado à lista de resultados.
collect_and_shuffle
- Coleta os resultados do mapeamento em um defaultdict.
- Agrupa os valores associados a cada chave.
reduce_worker
- Executada por cada thread de redução.
- Calcula a soma dos valores associados a uma chave e armazena o resultado.
distributed_mapreduce
Gerencia todo o processo de MapReduce distribuído:
- Divide o texto em chunks para os mapeadores.
- Inicia threads de mapeamento para processar cada chunk.
- Aguarda todas as threads de mapeamento terminarem.
- Coleta e redistribui os resultados do mapeamento.
- Inicia threads de redução para processar cada conjunto de valores associados a uma chave.
- Aguarda todas as threads de redução terminarem.
- Retorna os resultados finais da fase de redução.
Teste do código
- Cenário: Um exemplo simples de texto é processado usando a função distributed_mapreduce com 3 mapeadores e 3 redutores.
- Input:
hello world this is a test, for studying mapreduce hello world again, mapreduce again. - Output:
{'hello': 2, 'world': 2, 'this': 1, 'is': 1, 'a': 1, 'test,': 1, 'for': 1, 'studying': 1, 'mapreduce': 2, 'again,': 1, 'again.': 1}
Considerações Finais
Neste artigo estudamos em versão simplificada um script python que nos ajuda a compreender melhor a lógica de funcionamento desse importante modelo de processamento distribuído implementado pelo Google em 2004 e considerado base fundamental do processamento distribuído de grandes volumes de dados até os dias atuais.
Referências
- https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
- https://www.databricks.com/glossary/mapreduce
- https://ericcouto.wordpress.com/2013/06/06/mapreduce-python-parte-1/
- https://www.devmedia.com.br/big-data-mapreduce-na-pratica/32812
- https://medium.com/rodrigo-lampier/como-construir-um-programa-simples-de-mapreduce-2c8e6b0c2ccb
- https://medium.com/data-hackers/processamento-distribuído-de-dados-com-mapreduce-utilizando-python-mrjob-e-emr-c826a617f8b3