Moving Tables
Some Challenges and Continuities Between Batch and Streaming Data
Read in PortugueseIntroduction
 This article came from an analytical curiosity. While reading an important data engineering book, I ran into a brief discussion about "real-time data modeling" - maybe two pages in a 300-page book. Not a critique, just context.
This article came from an analytical curiosity. While reading an important data engineering book, I ran into a brief discussion about "real-time data modeling" - maybe two pages in a 300-page book. Not a critique, just context.
Despite a pretty interesting section with several points raised, one statement stood out: that it is practically impossible to apply traditional modeling techniques - associated with the idea of batch in that discussion - to real-time data. But is that really true? Are these data analytically so different? Are real-time data really that different from data produced in a batch model?
A direct yet abstract example appears in Spark Streaming architecture. The data stream (DStream) is, under the hood, a sequence of RDDs. In other words, a stream is a composition of mini-batches.
It may make more sense to think in terms of OLTP vs. OLAP. In that dichotomy, the biggest differences in data and modeling requirements seem to live. Not in batch vs. real time, but in transactions vs. analytics. Transactional needs usually demand lower latency than analytics, just to start the conversation.
At some point, even real-time data will need some logic and some format that enables and brings consistency and reliability to visualizations, analyses, and automated decisions. After all, data only make sense if they say something about reality, and to do that they need to represent it - which means they need some modeling.
In "traditional" data warehouse scenarios, with batch pipelines running smoothly for years, we know the most widespread modeling techniques in the market that tend to work well and are basically standards: dimensional modeling and data vault. But in a real-time or near-real-time data scenario? Have you ever asked how that happens? How does data modeling look if the data flow is truly constant and relentless?
This article is the result of a search to bring some clarity to questions like these. Real-time data mean, in one word: dynamism. Even if real time has a few seconds of delay, the speed is high enough to be considered a strategic business dimension today. For example, in financial fraud cases, a system with automated decisions and flags in near real time of a few seconds is a game-changer.
Dynamism

Flows that are closer and closer to real time do not just mean faster data. The nature of the data is also more dynamic; the management of changes and evolution in data structure becomes greater and more necessary.
I would say that, in general, the greater the volume and speed (closer to real time), the more data engineering benefits from good software engineering practices and automation across pipeline components - monitoring, quality, contracts, schema evolution, etc.
Whether in a pure batch scenario or something closer to real time, accuracy and consistency are fundamental - these attributes are definitely defined by data modeling. How do we deal with that in real-time scenarios? The answer to questions like "how to model data in real time" is strongly tied to solution architecture, and not only to the act of "modeling" data along the flow. In analytical windows, for example.
From an architectural standpoint, at some point the concept of lambda architecture will likely be activated - or something similar. Practice and literature show something close: real-time data are more about monitoring than modeling, but at some point in analytics some modeling will be necessary, and here it can feel like we are approaching the batch world again. Which raises the question: is the batch/realtime dichotomy a good starting point for thinking about modeling? My guess is maybe not. But that does not mean this point is meaningless and it raises good critical points for practitioners.
 Even if it is not a perfect starting point, in data engineering this discussion about modeling real-time data often falls into a real-time vs. data warehouse debate because time-based volume is fundamental in these questions and traditional modeling is more static.
Even if it is not a perfect starting point, in data engineering this discussion about modeling real-time data often falls into a real-time vs. data warehouse debate because time-based volume is fundamental in these questions and traditional modeling is more static.
On the other hand, these worlds are getting closer. Today we see a trend toward data warehouse platforms that can handle realtime workload, uniting both worlds in RTDW platforms.
Since data warehousing demands a specific architectural solution, why not shift the conversation a bit to a modeling approach that also considers the architecture?
Even in a full real-time environment, with monitoring practices on stream variations, there will hardly be no "rest" or batch environment that complements it. Users will still need historical data analysis. So how do we proceed? What is the trick to better manage and understand real-time data? Is there a difference?
One answer, as mentioned, is to think about data modeling associated with the architecture that supports operations. In that case, everything has its own specific semantics. And isolating each component may not be the best solution. Instead, seeking a more holistic view of how all data arrive and serve the business is more strategic and tends to generate better results. After all, each stream has the chance to become, somewhere else in the architecture, a table, and vice versa.
Where does a stream end and a table begin, definitively? Maybe that definition will never be as clear as our rational, somewhat perfectionist minds would like.
How do we proceed in these cases? Do we apply specific techniques for these scenarios? Does it make sense to think in terms closer to the batch world, such as Kimball dimensional modeling?
So far, we have discussed the fundamental differences between batch data and real-time data, highlighting how each approach has its place in modern data architectures. We observed that Lambda architecture often becomes a convergence point between these two approaches, providing a hybrid solution that takes advantage of both batch processing and real-time processing.
With that in mind, it is crucial to understand how data modeling, traditionally applied in batch scenarios, can be adapted and integrated to support the demands of real-time data. This adaptation requires not only a change in modeling techniques, but also a careful consideration of the underlying architecture that supports data operations. After all, performance is fundamental.
Before talking about real time itself, let us recall the idea of data modeling.
Data Modeling
A large part of data modeling is the process of creating an abstract representation of data and their relationships within a given domain or context. This representation facilitates understanding, manipulation, analysis, and visualization of data because it provides a common basis of meaning about the data and about what the data represent in reality.

We can understand it as the practice of defining and structuring data so they can be easily understood, manipulated, and analyzed. This involves creating diagrams or schemas that describe entities of interest, their attributes, and the relationships between them with the goal of facilitating data management and use, ensuring rules for data integrity and quality, and providing a consistent base for implementing information systems.
The different dimensions of modeling are conceptual, logical, and physical, and its main components are entities, attributes, relationships, and keys. Common applications include databases, general information systems, and data analysis.
Its challenges usually involve complexity, scalability of changes in data. Complexity is related to a manageable representation of different data domains in a broader context (a company, for example), and scalability is related to supporting increases in data volume. Change in data relates to changes in requirements and business environment that necessarily lead to changes in models.
It is not necessary to emphasize that data modeling is a critical process in computer science and information management - and not restricted to data engineering - because it provides the structure needed to store, organize, and use data effectively.
Therefore, applying data modeling techniques seeks to ensure that the information produced from those schemas is accurate, consistent, and useful to support organizational operations and decisions. And in real time, does that change? Or why would it have to change?
Traditional data modeling tends to focus more on historical or static data, while data monitoring focuses on real-time data. This does not mean that modeling historical data will become obsolete; on the contrary, it will continue to play a fundamental role in retrospective analysis and strategic decision making.
In other words, there is strong complementarity between historical data modeling and real-time data monitoring, rather than a complete replacement. In addition, in many cases, it is possible to adopt the mental model of more traditional data modeling in query situations, for example, to analyze real-time data that are still unstructured.
One interesting thing to remember is that many times when we deal with batch data, they are production logs that do not have enough volume yet to read in real time. Data that often, at higher volume, are more monitored.
Real-time Data Modeling
Regarding real-time modeling practices, the most commonly used are event streams. In this case, modeling can be based on assumptions such as time window modeling, events, created by materialized views or even updated via CDC.
Real-time data modeling is fundamental for systems that need to process and analyze large volumes of data as they are generated. Let us detail a bit more the techniques mentioned.
Event Streams as Tables
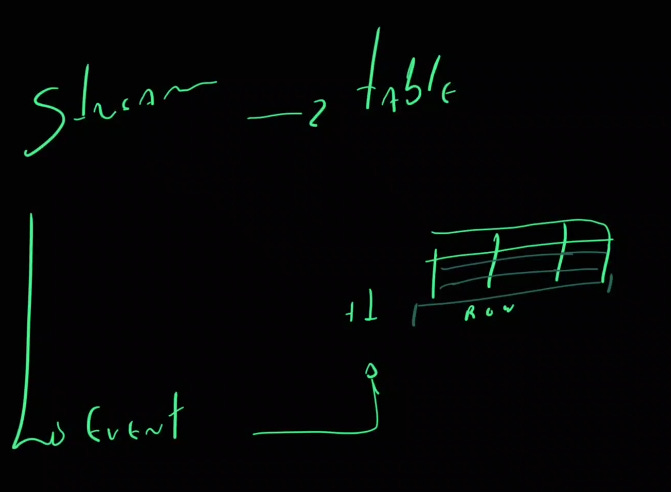
This approach allows treating continuous event streams as if they were tables in a database, making queries and aggregations easier. Some common approaches are:
Time Window Based Modeling
- Sliding Windows: The window moves continuously, considering a fixed time period for each new analysis. Ideal for continuous monitoring.
- Tumbling Windows: Fixed time windows that do not overlap. Each event belongs to a single window, useful for periodic aggregations such as daily counts.
- Session Windows: Group events based on activity sessions, where the window is determined by periods of inactivity.
Event States and Incremental Processing
- Intermediate States: Keep data state in memory for continuous calculations.
- Incremental Processing: Updates are made as new events arrive, recalculating only what is needed, which is efficient for large volumes of data.
Materialized Views
Precomputed tables that store results of frequent or complex queries. The views are updated as new data arrive, providing fast responses to complex queries.
Change Data Capture (CDC)
Technique to capture and apply changes in data from source systems, reflecting those changes in real time in destination systems, such as databases or streaming systems. Essential to keep synchronization between different systems.
These approaches are fundamental for systems that handle real-time data, supporting efficiency, accuracy, and scalability for a wide range of use cases.
From a tooling standpoint, it is common to see solutions heavily based on Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Beam, Google Dataflow, etc. Tools specifically prepared to handle the workloads of a distributed streaming platform, storing and processing data.
Next, we unfold a simple and didactic practical example, so we can reflect a bit more on what we have discussed so far with some more tangible reference in code.
Come along...
Practical Example
from pyspark.sql import SparkSession
from pyspark.sql.functions import window, col, count, first
import logging
#Configuring logging level
logging.getLogger("py4j").setLevel(logging.ERROR)
#Creating the Spark session
spark = SparkSession.builder \
.appName("StreamingDimensionalModelExample") \
.getOrCreate()
#Setting Spark logging level
spark.sparkContext.setLogLevel("ERROR")
#Read stream from rate source
purchaseStream = spark.readStream \
.format("rate") \
.option("rowsPerSecond", 5) \
.load() \
.selectExpr("value as sale_id",
"CAST(value % 10 AS STRING) as product_id",
"CAST(value % 5 AS STRING) as customer_id",
"concat('Product', value % 10) as product_name",
"concat('Customer', value % 5) as customer_name",
"timestamp")
#Calculate sum of sales by product_id
sales_sum = purchaseStream.groupBy("product_id") \
.agg(count("sale_id").alias("total_sales"))
#Write the result to console
query = sales_sum.writeStream \
.outputMode("update") \
.format("console") \
.option("truncate", "false") \
.start()
query.awaitTermination()
The Event
{
"sale_id": "1",
"product_id": "1",
"customer_id": "1",
"product_name": "Product1",
"customer_name": "Customer1",
"timestamp": "2024-05-28T12:00:00"
}
The Stream
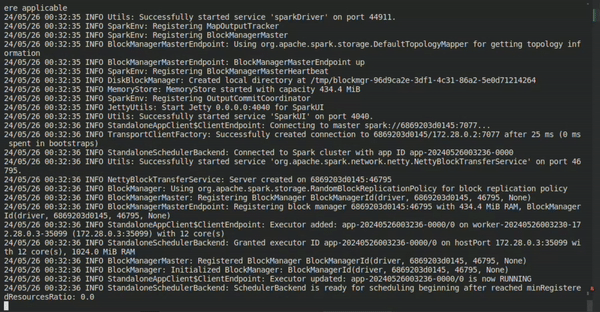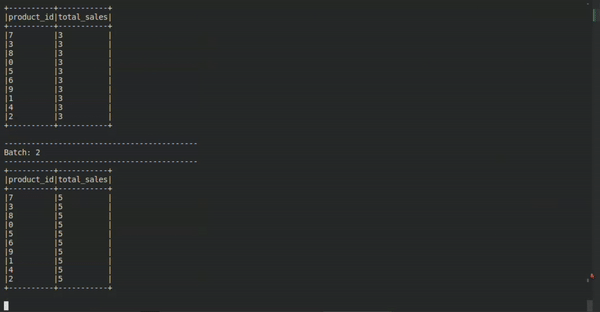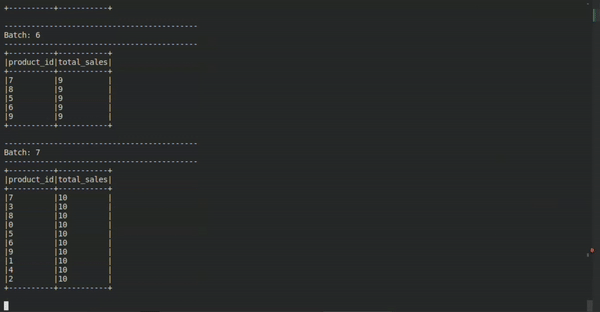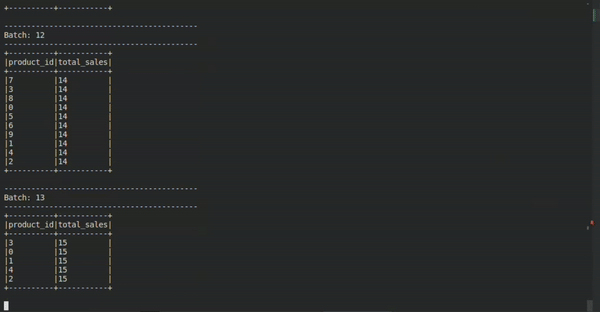
In this very short example, we can apply the mindset known through the Kimball technique, for example. Something that can make life easier for the analyst or engineer when they need to correlate or apply business rules, or with an existing model, for example.
We can use more traditional models with some freedom, even as mental mediator models to mediate the static world and the world in flow. In this case, we receive an event stream and model this data to extract the aggregated value of the total quantity of products sold by each product category in real time.
How does this happen? One way to interpret this modeling is by seeing the "product" dimension and the "sale" fact as concatenated in an aggregation from an event stream (which we already understood is like a moving table).
The "batch" rationale (modeling)
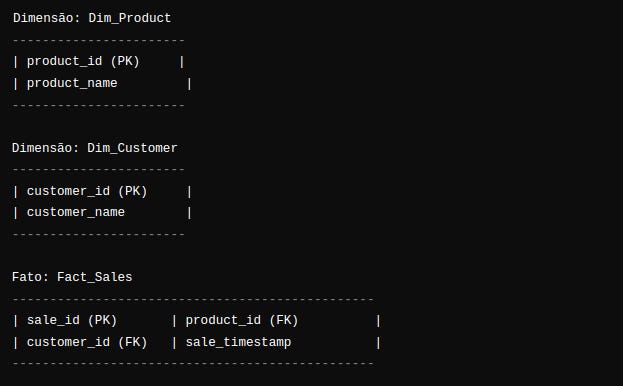
See how in this description we can reasonably describe a possible modeling rationale behind the query that shows our expected result in the console.
Of course, there is no way to assert and much less guarantee in practice that relational (batch) modeling sustains performance and scalability in any and all real-time systems.
However, this continuity between the static and streaming worlds is reinforced by the trend of data warehouses that process real-time workloads, which reinforces to some extent the need to combine "traditional" modeling reasoning to facilitate analytical reasoning, even without necessarily creating a complete and closed model in direct stream analysis. These points can indicate that the future may not be so different in terms of data modeling, but of course architecture, storage, and processing strategies are different and need to be considered according to each specific context and requirement, and deserve specific focus.
Final Considerations
Thinking in relational terms when analyzing data streams is not uncommon, especially when integrating real-time data with existing systems that already adopt relational models, such as relational databases or data warehouses. However, the degree to which relational modeling is applied can vary depending on the context and the specific requirements of the project.
Here are some situations in which thinking in relational terms when analyzing data streams may be more common:
- Integration with legacy systems: If you are integrating real-time data with legacy systems that use relational databases, it is natural to think in relational terms to facilitate integration and communication between systems.
- Consistency with existing models: If your organization already has established relational data models to represent business information, it may make sense to apply a relational approach when dealing with real-time data streams, to maintain consistency and familiarity with existing models.
- Complex analytics requirements: In some cases, it may be necessary to perform complex analyses that benefit from relational modeling capabilities, such as queries involving multiple tables or join operations between different real-time data sources.
On the other hand, in scenarios where the focus is on event and data flow analysis in real time, it may be more effective to adopt event-oriented data models or data flow models that focus on capturing and analyzing individual events rather than relationships between entities.
In summary, thinking in relational terms when analyzing data streams can be beneficial in certain contexts, especially when integrating with existing systems or facing complex analytics requirements. However, the most appropriate approach depends on the specific project requirements, the technologies involved, and the organization's preferences regarding data modeling.
References
- Johanna Vainio. "Data Ingestion and Data Modeling for Business Real-time Processing", 2024. https://www.agiledataengine.com/blog/data-ingestion-and-data-modeling-for-business-real-time-processing
- Joe Reis & Matt Housley. "Fundamentals of Data Engineering". O'Reilly, 2022.
- Justin Hayes. "An Overview of Real Time Data Warehousing on Cloudera", 2020. https://blog.cloudera.com/an-overview-of-real-time-data-warehousing-on-cloudera/
- Tyler Akidau, Slava Chernyak, and Reuven Lax. "Streaming Systems". O'Reilly, 2018.
- Martin Kleppmann. "Designing Data-Intensive Applications". O'Reilly, 2017.
- Nathan Marz and James Warren. "Big Data: Principles and Best Practices of Scalable Realtime Data Systems". 2015.
- Kenneth M. Anderson. "Lambda Architecture". CSCI 5828: Foundations of Software Engineering, 2014. https://home.cs.colorado.edu/~kena/classes/5828/f14/lectures/29-lambdaarchitecture.pdf
- Byron Ellis. "Real-time Analytics". Wiley, 2014.
- Apache Flink Documentation https://nightlies.apache.org/flink/flink-docs-stable/
- Apache Kafka Documentation https://kafka.apache.org/documentation/
- Apache Spark Documentation https://spark.apache.org/docs/latest/streaming-programming-guide.html